As a long-time perspectives shop, we have some specific formulas that have become standard practice for users. One that we are currently unable to replicate in Slice is using a DBS with a DBR. The purpose is to add in the desired value in the file to what is already loaded. Often analysts are provided large spreadsheets that have non-unique rows (we call it duplicate rows) where the data is different on each row but both need to be loaded (summed) when loaded. To avoid manual checks and summations, Perspectives allowed the following:
DBS(value+DBR())
This increments in the values to provide the expected result. In Slice, this works only if you are adding new values to values that are already committed in the cube, but not to load in incremental values from the spreadsheet. It still takes the last one loaded.
A simple example is when provided Employee hours for budget, the same employee/organization is provided on two rows. Planners want to see the different rows, but when loading into TM1, this causes a DBS issue as last one in wins. In this example 5 for January instead of 15. Using a DBS(Value +DBR()) in perspectives loads in the 10 first and then loads in the 5 +10 second for a total of 15. Currently in Slice, this does not work with DBS Send since, I assume, it is batching the request instead of Perspectives which evaluates each cell when using the DBS/DBR formulas. It is slower but serves a valuable function to avoid manual file updates.
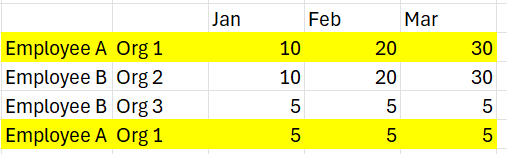
Does anyone have an alternative approach that works for them in Slice?